

Clinicians are increasingly turning to AI models for clinical decision support (67% of physicians in the US use AI daily) [1]. However, most evaluations of AI models rely on synthetic or exam-style benchmarks that fail to capture the reality of clinical uncertainty. Independent, specialist-validated benchmarks are needed to assess clinical safety and appropriateness in real-world care settings.
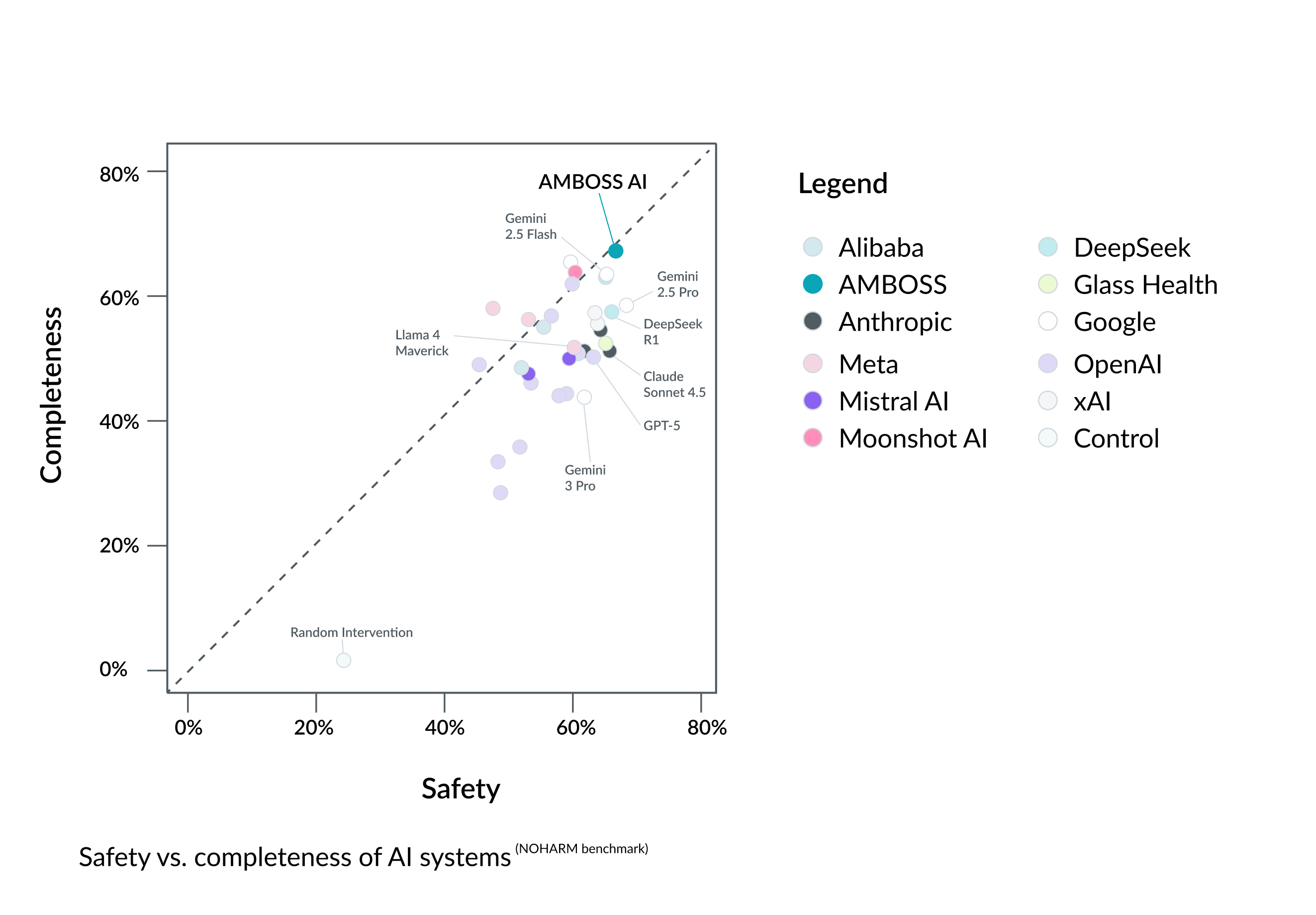
The NOHARM benchmark evaluated 31 AI systems using 100 real clinical cases derived from primary care to specialist consultations across 10 medical specialties[2]. The cases intentionally preserved incomplete information and real-world ambiguity.
Model outputs were evaluated for clinical appropriateness (benefit vs. harm) using 12,747 expert annotations provided by 29 board-certified physicians. Performance was assessed across safety and completeness dimensions.
AMBOSS AI Mode (LiSA 1.0) ranked #1 overall in clinical safety benchmark among the 31 evaluated AI systems. It demonstrated consistently strong performance across realistic clinical scenarios and ranked in the top tier across evaluated dimensions.
The performance of AMBOSS AI Mode (LiSA 1.0) in the benchmark reflects an approach to clinical AI that prioritizes:
In an independent, specialist-validated evaluation using real clinical cases, AMBOSS AI Mode ranked highest overall among the 31 AI systems assessed using the NOHARM benchmark. Benchmarks such as NOHARM provide essential evidence for responsible adoption of AI in clinical care.
The NOHARM benchmark was developed by academic researchers at Stanford University School of Medicine, Harvard Medical School, and the ARISE AI Research Network. AMBOSS did not fund the study, and AMBOSS personnel were not involved in its design or analysis.
[1] David Wu et al. MAST: Medical AI Superintelligence Test. ARISE. Accessed April 9, 2026. https://arxiv.org/abs/2512.01241v1
[2] The 2025 Physicians AI Report. Offcall. Accessed April 9, 2026. https://2025-physicians-ai-report.offcall.com/







© 2026 AMBOSS. All rights reserved.